NVIDIA Releases Cosmos 3: A Two-Tower Mixture-of-Transformers Foundation Model Unifying Physical Reasoning, World Generation, and Action Generation
重點摘要
NVIDIA AI team have released Cosmos 3. It is a family of omnimodal world models for physical AI. The models combine physical reasoning, world generation, and action generation. All three capabilities live inside one open model. NVIDIA open sourced the checkpoints, training scripts, deployment tools, and datasets. The Cosmos 3 release targets robotics, autonomous vehicles, and warehouse monitoring teams. NVIDIA Cosmos 3 Physical AI systems must understand the world before acting in it. Robots and vehicles need to perceive, predict, and then act. Earlier Cosmos releases split these jobs across separate models. Cosmos 3 unifies them with a Mixture-of-Transformers (MoT) architecture. The architecture is built around two towers. The reasoner tower is a vision-language model (VLM). It interprets
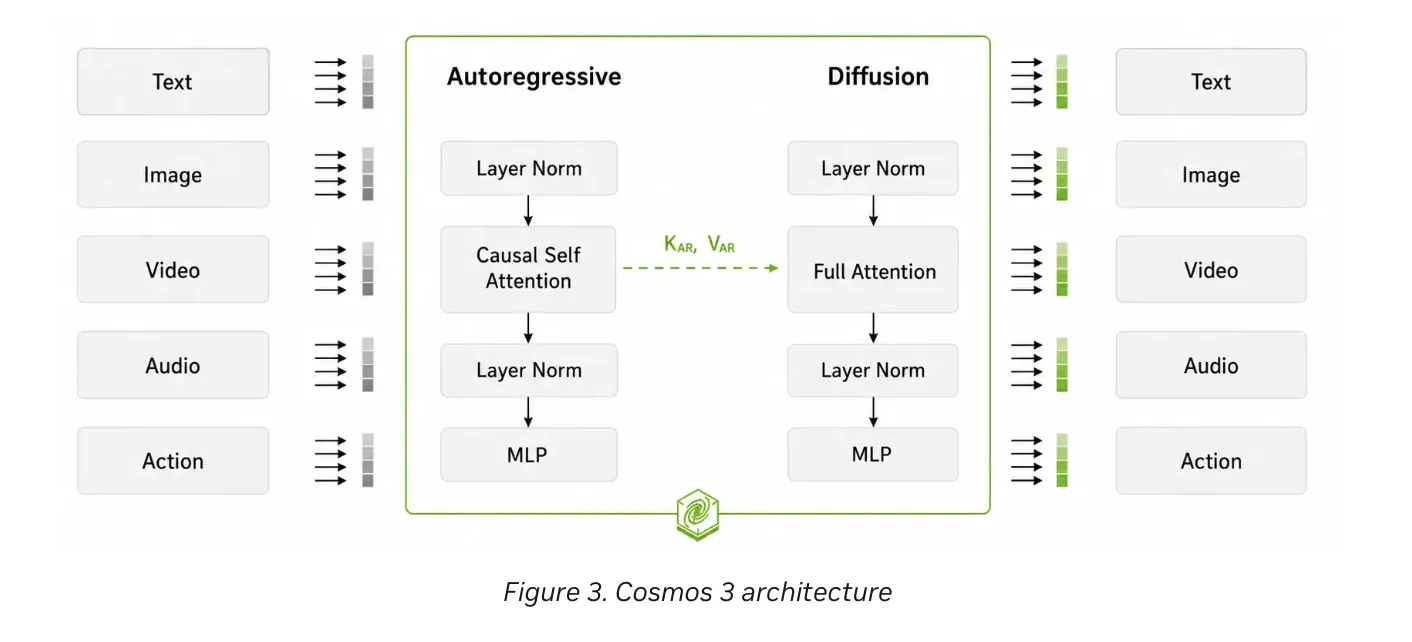
NVIDIA AI team have released Cosmos 3. It is a family of omnimodal world models for physical AI. The models combine physical reasoning, world generation, and action generation. All three capabilities live inside one open model. NVIDIA open sourced the checkpoints, training scripts, deployment tools, and datasets. The Cosmos 3 release targets robotics, autonomous vehicles, and warehouse monitoring teams. NVIDIA Cosmos 3 Physical AI systems must understand the world before acting in it. Robots and vehicles need to perceive, predict, and then act. Earlier Cosmos releases split these jobs across separate models. Cosmos 3 unifies them with a Mixture-of-Transformers (MoT) architecture. The architecture is built around two towers. The reasoner tower is a vision-language model (VLM). It interprets images, videos, and text using an autoregressive architecture. It understands motion, object interactions, and other physical context. NVIDIA team describes this tower as the model’s brain. The generator tower produces future observations and action sequences. It uses a diffusion-based process for physics-aware video and actions. These outputs are conditioned on the reasoner tower’s understanding. Information flows one way, from reasoner to generator. The reasoner can run alone. The generator always activates both towers for guided generation. A single model can therefore handle reasoning and generation together. https://developer.nvidia.com/blog/develop-physical-ai-reasoning-world-and-action-models-with-nvidia-cosmos-3 The Model Family NVIDIA team describes three model scales: Edge, Nano, and Super. Each uses the dual-tower Mixture-of-Transformers design. The two towers are initialized from pre-trained Qwen3-VL weights. That roughly doubles the parameter count of the backbone transformer. Cosmos3-Nano is a 16B model built on a dense 8B transformer. It adapts the Qwen3-VL 8B architecture. Nano targets efficient inference on workstation GPUs. It runs on hardware like the NVIDIA RTX PRO 6000. That suits real-time robotics and on-device physical AI. Cosmos3-Super is a 64B model built on a dense 32B transformer. It adapts the Qwen3-VL 32B architecture. Super targets datacenter GPUs, including NVIDIA Hopper and Blackwell. It fits large-scale synthetic data generation and advanced reasoning. This release ships Nano and Super, along with task-specific variants. These include Super Text2Image, Super Image2Video, and Nano-Policy-DROID. How the Unified Design Works Both towers share one transformer architecture and a joint attention operator. They use a 3D multimodal rotary position embedding (mRoPE). mRoPE aligns video, audio, and action tokens on one temporal axis. In Reasoner Mode, tokens pass through causal self-attention. This enables next-token prediction for perception, planning, and reasoning. In Generator Mode, noisy tokens are denoised through full attention. The autoregressive tokens are never updated by the diffusion tokens. The model treats action as a core modality with dedicated action tokens. Supported inputs include text, image, video, and JSON action arrays. Outputs include images, video, synchronized sound, action states, and text. The reasoner follows Qwen3-VL-compatible message conventions for vision inputs. Generation supports 256p, 480p, and 720p resolution tiers. Frame counts range from 5 to 300, defaulting to 189. That equals about 7.9 seconds of video at 24 FPS. Sound is generated as stereo AAC at 48 kHz. Action conditioning spans camera, vehicle, egocentric, single-arm, dual-arm, and humanoid embodiments. Each embodiment uses a fixed action dimension, such as 9D for cameras. The Benchmark Case NVIDIA team evaluated Cosmos 3 across reasoning and generation suites. On reasoning, Super and Nano lead VANTAGE-Bench at their respective tiers. VANTAGE-Bench tests VLMs on real-world fixed-camera footage. It covers warehouses, transportation, and smart spaces. Cosmos 3 also tops the Traffic Anomaly Reasoning (TAR) leaderboard. TAR is the official leaderboard for AI City Challenge 2026 Track 3. On generation, NVIDIA reports open-source state-of-the-art results. Cosmos 3 is the open-source SOTA on R-Bench. It also leads PAI-Bench, Physics-IQ, and RoboLab on public leaderboards. On Artificial Analysis, it leads two open-source leaderboards. These cover text-to-image and image-to-video without audio. NVIDIA team also introduced its Cosmos Human Evaluation framework, called HUE. HUE decomposes each generated video into yes/no fact questions. It scores four dimensions across seven physical AI domains. The dimensions are semantic alignment, physical laws, geometric reasoning, and visual integrity. A VLM pipeline drafts the questions, and human experts refine them. Marktechpost’s Visual Explainer marktechpost@guide ~ /nvidia/cosmos-3 01 / 09 DEVELOPER GUIDE · PHYSICAL AI NVIDIA Cosmos 3 Open omnimodal world models for physical AI. Released May 31, 2026. One model for physical reasoning, world generation, and action generation. Mixture-of-Transformers Open weights OpenMDW-1.1 Use ← → or swipe to navigate 01 · WHAT IT IS A unified model for understanding and generation Cosmos 3 is a family of omnimodal world models for physical AI. Earlier Cosmos releases split jobs across separate models. Cosmos 3 unifies them in a single open model. Physical reasoning over images, video, and text. World generation of physics-aware video and sound. Action generation for robots and autonomous systems. Subsumes VLMs, video generators, world simulators, and world-action models. 02 · ARCHITECTURE Two towers, one transformer REASONER TOWER An autoregressive vision-language model (VLM). It interprets motion, object interactions, and physical context. NVIDIA calls it the model’s brain. GENERATOR TOWER A diffusion-based path for physics-aware video and actions. It is conditioned on the reasoner’s understanding. Information flows one way, reasoner → generator. Both towers share a 3D multimodal RoPE (mRoPE). 03 · MODEL FAMILY Pick a size for your hardware Cosmos3-Nano 16B total (dense 8B, Qwen3-VL 8B). Workstation GPUs like RTX PRO 6000. Real-time robotics. Cosmos3-Super 64B total (dense 32B, Qwen3-VL 32B). Datacenter Hopper and Blackwell GPUs. Large-scale SDG. Cosmos3-Edge 4B total (dense 2B). On-device scale. Planned for a later release. Plus variants: Super-Text2Image, Super-Image2Video, and Nano-Policy-DROID. 04 · MODALITIES Inputs, outputs, and generation settings Inputs: text, image, video, and JSON action arrays. Outputs: image, video, synchronized sound, action states, text. Resolution: 256p, 480p, 720p. Sound: stereo AAC at 48 kHz. Length: 5 to 300 frames; default 189 (about 7.9s at 24 FPS). Embodiments: camera, vehicle, egocentric, single-arm, dual-arm, humanoid. 05 · BENCHMARKS What NVIDIA reports REASONING Nano and Super lead VANTAGE-Bench at their tiers. Cosmos 3 tops TAR, the AI City Challenge 2026 Track 3 leaderboard. GENERATION Open-source SOTA on R-Bench. Leads PAI-Bench, Physics-IQ, and RoboLab. Top open-source on Artificial Analysis text-to-image and image-to-video. HUE evaluates videos with yes/no fact checks across four dimensions and seven domains. 06 · OPEN RELEASE Everything ships open Checkpoints for Nano, Super, and task-specific variants. Six SDG datasets: robotics, physics, spatial reasoning, human motion, driving, warehouses. Training recipes: SFT plus action post-training. Action modes: forward dynamics, inverse dynamics, and policy generation. License: OpenMDW-1.1. 07 · DEPLOYMENT Run it in production NIM microservices: Reasoner NIM available now; Generator NIM later. Quantization: BF16, FP8, and NVFP4. NVFP4 gives up to 2x speedup. Serving: the Reasoner NIM stack is built on vLLM. Efficient Video Sampling (EVS): prunes redundant video tokens at inference. Use Diffusers and Transformers for research; vLLM-Omni and vLLM for serving. 08 · LIMITATIONS & START Know the caveats, then build Outputs can show temporal inconsistency, unstable motion, object morphing, i
Related
相關文章

重估比亞迪,從智駕開始
比亞迪正從銷量龍頭轉向智慧化玩家,全力加速布局智慧駕駛技術,並將「天神之眼」高階智駕系統下放至親民車型,意味著智駕將成為大眾市場標配。若轉型成功,比亞迪的估值邏輯可能從傳統車廠轉向科技公司,甚至帶動本益比重估與售後訂閱服務收入。不過,比亞迪仍面臨軟體整合、成本控管及與競爭對手在智駕體驗上的差距等挑戰。
以 AI 之光築夢老區教育 聯想 AI 智慧教室落地福建寧化
這篇消息聚焦「以 AI 之光築夢老區教育 聯想 AI 智慧教室落地福建寧化」。原始導語提到:### 重點整理 聯想集團與中國兒童少年基金會攜手,在福建寧化一所位於中央紅軍長征出發地的學校,捐建了「AI 智慧教室」。這項計畫讓偏鄉學童有機會接觸最前沿的人工智慧課程,翻轉過去資訊設備落後的學習環境,也象徵科技企業對革命老區教育的具體支持。 ### 背景脈絡 寧化縣是福建著名的革命老區,也是中央紅軍長征的重要出發點之一。當地許多學校因地處偏遠,長期面臨教育資源不足、師資老化、資訊設備缺乏等問題。在國家推動「教育數位轉型」與「AI 人才培育」的趨勢下,企業與公益組織的合作成為補足城鄉數位落差的關鍵力量。聯想集團過去已在中國多地推動智慧教育方案,此次選擇在寧化落腳,除了呼應紅色歷史的文化象徵意義,也展現科技扶貧與教育公平的具體實踐。 ### AI 智慧教室的內涵與特色 這間「AI 智慧教室」不僅是硬體設備的更新,更結合了聯想在 AI 教學平台、互動學習軟體與遠距教學系統上的技術。透過智慧白板、AI 助教與機器人教具,學生可以體驗語音辨識、影像辨識、基礎程式設計等課程,讓山區孩子的第一堂 AI 課,真的與一線城市的教學內容同步。這項捐贈也包含教師培訓,確保當地教師能善用科技工具,而非只是擺設。 ### 可能影響:縮短城鄉數位鴻溝 對於寧化當地的學童而言,AI 智慧教室的落地,意味著他們不再只能從課本上認識 AI,而是能親手操作、實際感受科技如何改變生活。這有助於提升學生的學習動機與數位素養,也為未來升學或就業鋪路。從更大層面來看,這類計畫能帶動更多企業關注偏鄉教育,形成「科技+公益」的良性循環,並為其他老區或偏遠地區的數位教育提供可複製的模範。 ### 可能影響:啟發在地教育創新 除了學生直接受惠,教師也能透過智慧教室的數據回饋,掌握學生的學習進度與困難點,進而調整教學策略。過去偏鄉教師往往因資源不足而難以導入創新教學法,現在有了 AI 輔助工具,反而有機會發展出結合當地文化與科技的特色課程,例如用 AI 分析客家方言或紀錄長征歷史,為教育注入在地生命力。 ### 讀者可關注的後續 接下來值得留意的是,聯想是否會在其他革命老區或偏鄉複製此模式,並長期追蹤學生的學習成效。另一方面,中國兒童少年基金會是否會推出配套的獎學金或課後輔導計畫,幫助這些孩子持續接觸 AI 領域。此外,當地政府與教育部門是否會將這間智慧教室作為區域示範點,進一步推廣至周邊學校,也是觀察重點。 ### 結語 AI 智慧教室的落成,不只是硬體捐贈,更是一場教育平權的實踐。當革命老區的孩子也能與城市學生一樣,擁有開啟 AI 世界大門的鑰匙,科技便不再是遙遠的想像。期待這道光不僅照亮寧化,更能點燃更多偏鄉孩子對未來的信心。 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。

英格蘭考試監管機構警告:智能眼鏡、隱形耳機或助長作弊行為
這篇消息聚焦「英格蘭考試監管機構警告:智能眼鏡、隱形耳機或助長作弊行為」。原始導語提到:智能手機已經讓考試作弊有所增加,而下一波可穿戴設備可能讓問題更加嚴重,並危及英格蘭學校資格考試體系的公信力。 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。

花1500美元,讓AI“黑”自己的App:GPT-5.5成功率70%,部分模型0分交卷
## 花1500美元請AI當駭客:GPT-5.5成功率高達七成,部分模型直接繳白卷 近期一項針對大型語言模型「自動化滲透測試」能力的研究引發關注。研究團隊設計了一個專門用來評估AI模型尋找軟體漏洞的「Bug靶場」,並邀請多個主流模型嘗試攻擊一款由AI生成的應用程式。結果顯示,只要付出約1,500美元的成本,GPT-5.

AI眼鏡的可能性:讓生活場景成為學習場景
AI 眼鏡能將即時資訊疊加在使用者視野中,讓購物、散步等日常場景變成即時學習的機會,實現「所見即所學」的教育模式。此技術呼應杜威「教育即生活」的理念,可能打破學校與生活的界線、降低學習門檻,但也帶來過度依賴、隱私風險與數位落差等隱憂。

北京 19 個路口上線 AI 紅綠燈,擁堵指數下降約 19%
北京海淀 19 個路口上線 AI 紅綠燈,能根據實時路況自動調整綠燈時長,最高可延長 15 秒。系統上線後,四道口地區整體車速提升約 21%,擁堵指數下降 19% 左右。#智慧交通##AI 紅綠燈#